How to Scrape Dynamic Websites with Python


What are Dynamic Websites in the Context of Web Scraping?

Dynamic websites or web pages in the context of web scraping are web pages that don’t send their full content in the initial response sent to you when you request them. Some of them will present the static section of the page such as the header and footer in the first response. The main content will then be loaded using Javascript (AJAX) which is either done automatically or because of your interaction with the page.
Because of Javascript involvement, you can’t access these pages without Javascript as they will return a blank response or request you turn on Javascript execution. This means if you are in the business of turning off Javascript in other to avoid tracking, you can’t do that with dynamic websites. At first, this looks like a bad thing but from a user point of view, this is great for user experience as it saves bandwidth and they don’t have to wait until a page loads completely before they can start interacting with it.
Unfortunately, while this is great for the users, it is a pain for web scrapers. This is because web scrapers have been traditionally developed to scrape static pages that the HTML contains the full page content on load. These traditional web scrapers can’t scrape dynamic pages with the traditional approach — you need a dynamic scraping method for dynamic pages.
Ways to Scrape Dynamic Pages with Python
Most times, when scraping dynamic pages with Python is mentioned, the minds of most scraper developers will race to Selenium and its likes such as Puppeteer and Playwright. Sure these tools work, but they are not an easy option for you in terms of development and they have their performance issues. There is another method you should first utilize known as the reverse engineering approach. It is when this does not work you can switch to using Selenium. In essence, there are two ways you can scrape dynamic content with Python. Either you use reverse engineering or you use Selenium or an alternative. Let's take a look at how to do each of these.
Method 1: Reverse Engineering
There should be a standard name for this procedure but since I didn’t see one, I had to resort to using this name as that is the best term to describe it. What reverse engineering does is it tries to decode and discover all the web requests sent by the Javascript code of the page which returns the content as a response. Something interesting happens behind the scenes that is responsible for the dynamic nature of dynamic web pages. This interesting thing is requests are being sent to the server to retrieve the content that wasn’t sent initially.
If you can find the request URL, payload, and other details, you should be able to replicate the same request using traditional scraping tools such as Python’s requests and BeautifulSoup. In most instances, this is even more efficient than the traditional method of downloading the full web page content before scraping. This is because, on this page, the responses are usually in JSON and contain just the data for that specific piece of information which helps you save more bandwidth than the traditional method. It is also faster and offers you the best performance because of the same reason. However, you need to know how to identify the specific requests and how to replicate them. Let me show you how to do this with an example.
Step By Step Guide on How to Reverse Engineer Websites for Scraping
I will use a test web page that is dynamic and requires your action to display content. The web page is https://www.scrapethissite.com/pages/ajax-javascript/. This site as a whole is dedicated to web scraping guides and there are different web pages to help you build your web scraping skills. This page presents a list of great films for each of the years on the page but you will have to click on each year before this is displayed.
If Javascript is enabled and you click on the link for a year, you will see a table with the details for films for that year. The moment you disable Javascript and you click on the same link, nothing will happen. This is a typical behavior of Ajaxied dynamic web pages and suits perfectly for us to use as a guide on how to scrape Ajax pages.
So how will I scrape the list of sports on the left-hand side of the page? Well, that is what I will show you in this section.
Step 1: Install the Necessary Libraries
Like I mentioned earlier, I wouldn’t be using modern scraping libraries in this reverse engineering method, I will use the traditional tools but use a different technique to make them useful. I will be using the Requests library. You can install it using the “pip install requests” if you already have Python installed on your device. If you don’t, first install the latest version of Python from its official website.
Step 2: Check Network Activities in Your Browser Developer Tool
All popular browsers come with development tools on desktops. I am using Chrome in this guide. To access this tool, visit the https://www.scrapethissite.com/pages/ajax-javascript/. and right-click on anywhere on the page. Choose the “Inspect Element” and an interface will show on the right side of the page. That is the developer tool, and choose the Network tab as that is where you will see all of the network activities including all of the requests sent by the website’s Javascript behind the scene and the responses returned. By now, all of the network activities for loading the page will have been completed.
Reload it and you will see a list of requests being sent. There are some tabs such as all, fetch/xhr. CSS, JS, and a few others. The one we are interested in is the “Fetch/xhr”, click it. Now go to the website at the left-hand side of the page and click on a year, you will notice a new entry in the network tab.
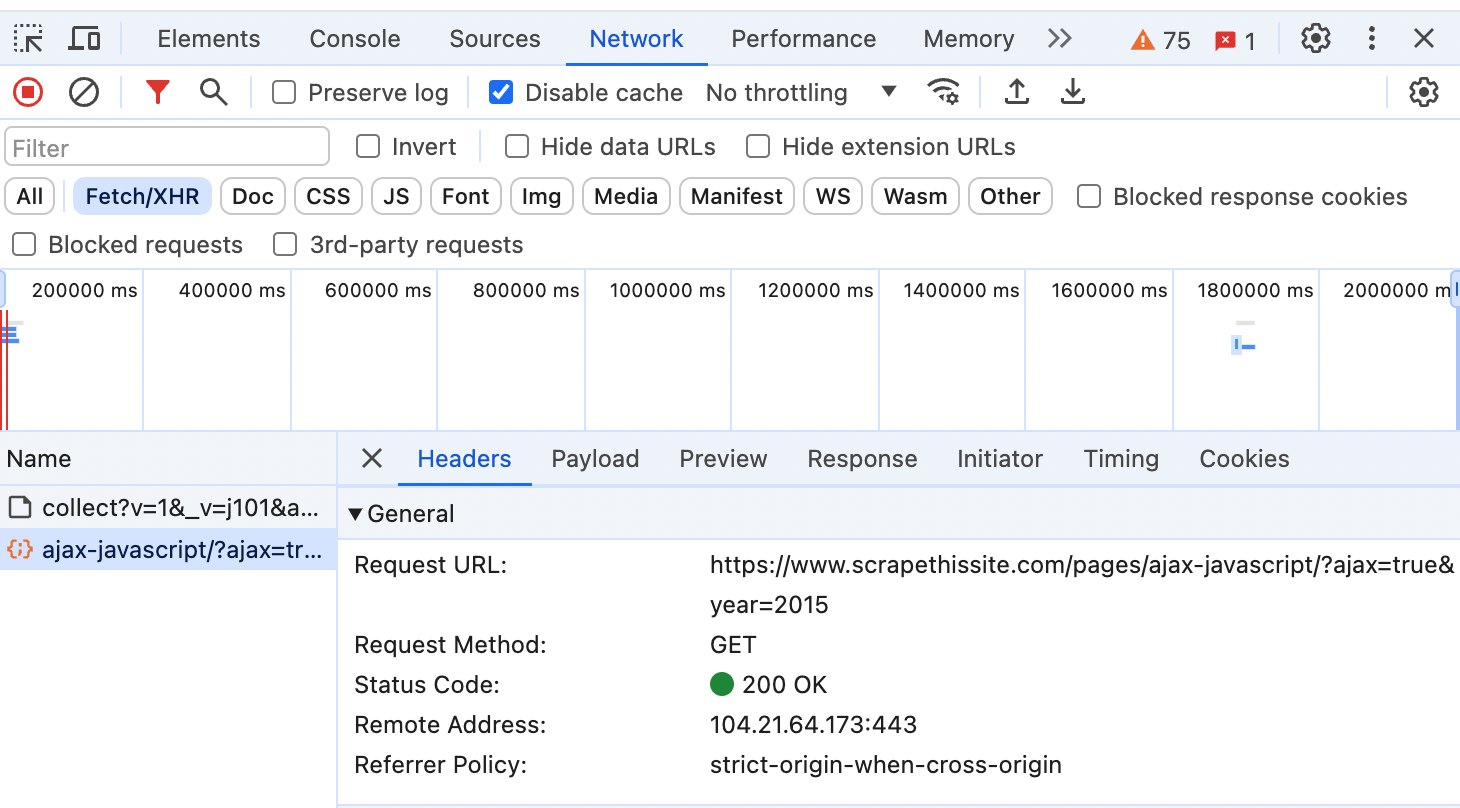
Click on this new entry and you will see a new interface with some tabs. By default, the headers tab is in view. You will see the request URL. You can scroll down to see the headers sent along the request. The Payload tab is for post requests which shows the data you send. Go to the Preview tab. There, you will see a preview of the response data.
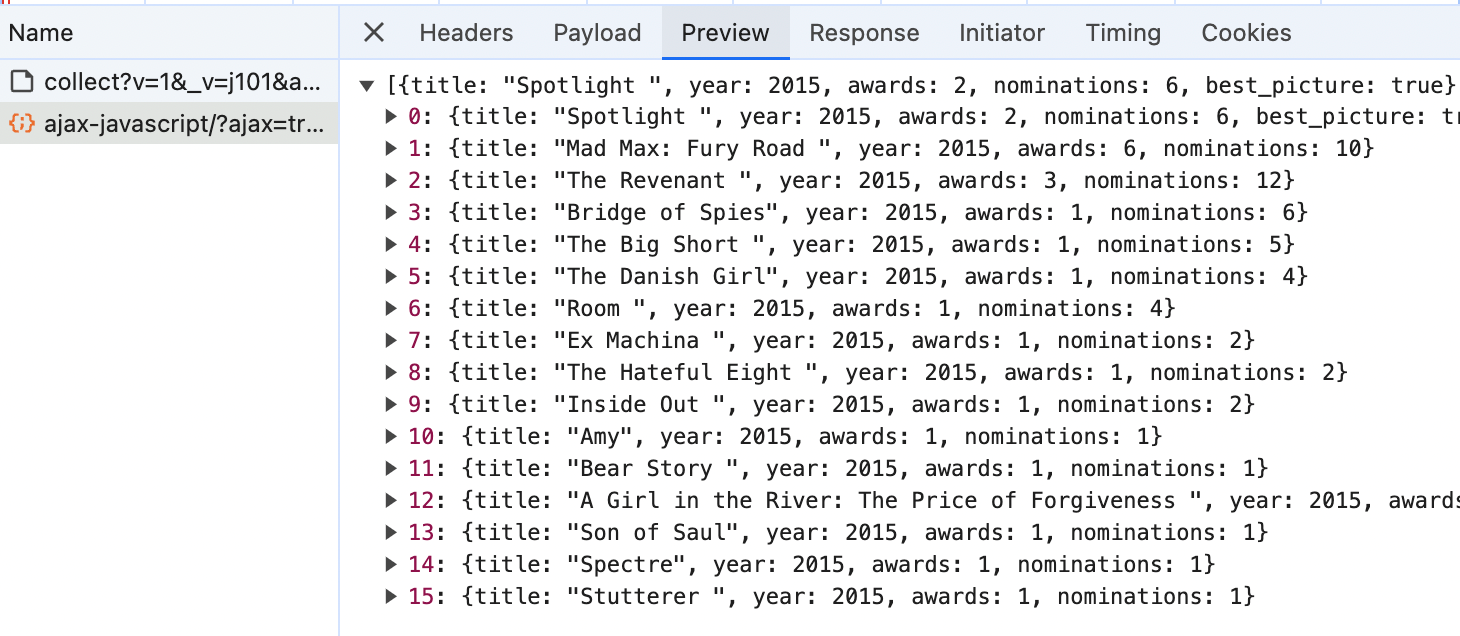
As you can see above, a list of movies contains information such as movie name, year, number of awards, nominations, and even the best picture that describes it. With this, we can see that we do not even need to use BeautifulSoup to parse this as the data is available in JSON. The URL for this is https://www.scrapethissite.com/pages/ajax-javascript/?ajax=true&year=2015. Now all we have to do is code a scraper, send a URL to this request and we will get a response in JSON we can use. Let me do that below.
Step 3: Use Requests to Scrape Content
With the URL information for the request that generates the data gotten above, all one has to do is to replicate the same request and you will get the required data.
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
}
url = "https://www.scrapethissite.com/pages/ajax-javascript/?ajax=true&year=2015"
movies = requests.get(url, headers=headers).json()
for movie in movies:
print(movie)
First, I use only requests, Beautifulsoup is not even included — this makes this method even simpler than the traditional method of using requests and Beautifulsoup. Since the response is in JSON, there is no need to convert the response to text and back to JSON as requests have support for the JSON method to convert a stringified JSON text to JSON/dictionary. If you run the above, you will get the below response.
That’s it, this is how easy it is to scrape dynamic websites using the reverse engineering method.
Method 2: Scraping Using Browser Automators
The actual standard for scraping dynamic websites is using a browser Automator such as Selenium or Puppeteer. Using either of these, you are able to access a website and automate events such as scrolling or clicking a button that will initiate requests by Javascript to send, receive, and render data on a page. The goal is to automate a browser to render the content on a page after which you can now scrape the content you need.
Selenium is the popular option here. It supports the popular languages for scraping including Python. It also supports more browsers than any other alternatives out there. The advantage Selenium has over using the reverse engineering method is that you don’t have to dig deep into the developer tool and don’t have to worry about malformed requests. However, it is slower and consumes more memory. You can reduce some of its side effects by using the headless mode which, though will automate your browser, will not have to physically render the browser for you to see.
Step by Step Guide on How to Scrape Dynamic Websites Using Selenium
Below are the steps to scrape the same content using Selenium.
Step 1: Install Selenium
Selenium is not part of the Python standard library and as such, you will need to install it. Installing and using Selenium is not like installing other libraries. First, you need to install it and then download a web driver that corresponds with the version of the browser you want to automate. To install Selenium, run this command in the command prompt/terminal “pip install selenium”.
For the web driver, you need to download and extract the executable in your system path. For this guide, just place it in the same folder as your script. Google Chrome users should click here —- for Firefox users, you can check the Mozilla Gecko driver page to download it. Safari users don’t need to install a driver in other to use it.
Step 2: Inspect Page for Relevant Element IDs and Classes
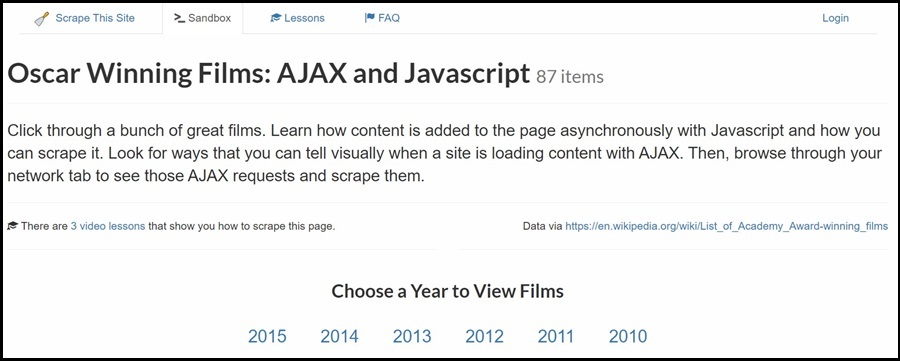
Now visit the same page (https://www.scrapethissite.com/pages/ajax-javascript/) and right-click the 2015 button then choose inspect element. You will see the ID of the link as (2015). This is what you will use to locate the button and click it. If the web page is a complex one, you will have to do a lot of traversing. However since the target is a simplified sample site, we don’t have to do a lot to reach our target.
Step 3: Code Web Scraper
Below is the source code for scraping the data using Selenium.
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
# Set up Chrome WebDriver
driver = webdriver.Chrome()
# Open the URL
url = "https://www.scrapethissite.com/pages/ajax-javascript/"
driver.get(url)
# Wait for the page to load
driver.implicitly_wait(10)
# Find the link with id "#2015" and click it
link = driver.find_element(By.CSS_SELECTOR, "#2015")
link.click()
# Wait for the new page to load after clicking
driver.implicitly_wait(10)
# Get the page source after clicking the link
page_source = driver.page_source
# Parse the page source using BeautifulSoup
soup = BeautifulSoup(page_source, 'html.parser')
# Find the table element
table = soup.find('table', class_='table')
# Find all rows in the table body
rows = table.find('tbody', id='table-body').find_all('tr', class_='film')
# Initialize a list to store the data
data = []
# Loop through each row and extract the data
for row in rows:
title = row.find('td', class_='film-title').get_text(strip=True)
nominations = row.find('td', class_='film-nominations').get_text(strip=True)
awards = row.find('td', class_='film-awards').get_text(strip=True)
best_picture = row.find('td', class_='film-best-picture').get_text(strip=True) if row.find('td', class_='film-best-picture').find('i') else ''
data.append({
'Title': title,
'Nominations': nominations,
'Awards': awards,
'Best Picture': best_picture
})
# Print the scraped data
for item in data:
print(item)
# After scraping, you can perform further actions or data processing as needed
# Close the browser window
driver.quit()
What the code above does is simple. It visits the page and waits for 10 seconds so all the initial elements will load fully after which it finds the 2015 link with the ID (2015) and click. It then waits for 10 seconds so the browser will get and render the content after it then fetch the HTML of the page and feed it to Beautifulsoup for parsing and data extraction.